

搜索引擎蜘蛛是什么?google搜索引擎优化
是搜索引擎抓取网页的程序,准确的叫“搜索引擎机器人”。
那为什么叫蜘蛛呢?这是因为搜索引擎的程序抓取互联网上的网页的时候,是顺着网页上的超链接进行的,从这个网页到另一个网页,从这个网站通过超链接到另一个网站,跟蜘蛛的爬行是一样的。所以互联网人员就把搜索引擎抓取网页的程序称为“蜘蛛”。
在互联网世界里,有很多个搜索引擎,每个搜索引擎都有各自的抓取程序——蜘蛛:
谷歌蜘蛛:Googlebot
百度蜘蛛:Baiduspider
360蜘蛛:360Spider
搜狗蜘蛛:Sogou web spider……
SOSO蜘蛛:Sosospider
雅虎蜘蛛:Yahoo! Slurp China
有道蜘蛛:YoudaoBot或者YodaoBot
MSN蜘蛛:msnbot-media
必应蜘蛛:bingbot
搜索引擎蜘蛛的工作原理?
1、最佳优先
最佳优先搜索策略按照一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关性,并选取评价最好的一个或几个URL进行抓取,它只访问经过网页分析算法预测为“有用”的网页。
存在的一个问题是,在爬虫抓取路径上的很多相关网页可能被忽略,因为最佳优先策略是一种局部最优搜索算法,因此需要将最佳优先结合具体的应用进行改进,以跳出局部最优点,据马海祥博客的研究发现,这样的闭环调整可以将无关网页数量降低30%~90%。
2、深度优先
深度优先是指蜘蛛沿着发现的链接一直向前爬行,直到前面再也没有其他链接,然后返回到第一个页面,沿着另一个链接再一直往前爬行。
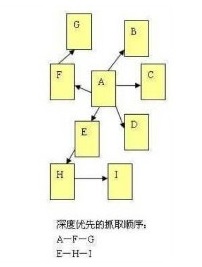
3、广度优先
广度优先是指蜘蛛在一个页面发现多个链接时,不是顺着一个链接一直向前,而是把页面上所有链接都爬一遍,然后再进入第二层页面沿着第二层上发现的链接爬向第三层页面。
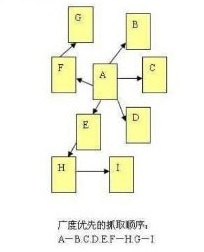
注:为了尽量多的抓取网页信息,深度优先和广度优先通常是混合使用的。
转载:第一页微信公众号“外贸新一周”